From Plain Machines to Container Orchestration: A Complete Explanation

If you'd like to trigger a room full of developers and operators, go in and tell them that they need container orchestration. Or tell them they don't need it. Either way, you'll begin a bloody war filled with snarky comments, long-winded anecdotes, and essay-length retorts.
"Is this a tool? A pattern? An ideological war??"
Being the Curious Cole that you are, you ask Google about it. What you get is the equivalent of most credit card or alcohol commercials - oh look, here's this amazing astronaut flying through space while simultaneously solving world hunger...buy our alcohol. Images of conferences and crowds, bubbly mascots, logos of massive companies...is this what it's like when you grab hold of container orchestration??
Well, you clearly want to know more, because this is obviously how you can become a bubbly mascot too right? So you crack open the documentation of whichever solution you've been convinced of and are stricken with overwhelm. Every piece of technical jargon imaginable is jam-packed into all points and paragraphs. Lifeless diagrams and rectangles sit atop dry, contextless definitions. Oh, and what's this...? "Self-Healing...?" Is this sorcery?? Nevermind, that just means it restarts things if they go down...
And so, in this post, we're going to attempt to clarify the idea of container orchestration in plain english. No, it's not a magic bullet (or a self-healing wizard with magic missiles), because it will not solve all of your problems. But no, it's not snake oil, because it can actually help.
However, in order to understand, let alone appreciate container orchestration, we need to look beyond the tip of the iceberg. We need to understand the players and pieces that make it possible. We'll swim below the icy surface waters to see what things make this glacial topic possible and useful. Let's dive in.
(Note: This is an interlude and belongs to my long series of posts Understanding Modern Architecture on AWS. Be sure to check out the rest of the posts in the series!)
Table of Contents
- Machines
- Virtual Machines
- Container Foundations
- Running Applications in Virtual Machines or Containers
- Scaling Out and Managing Virtual Machines
- Scaling out and Managing Containers
- Cluster Scheduling and Management
- Container Orchestration
- Other Posts in this Series
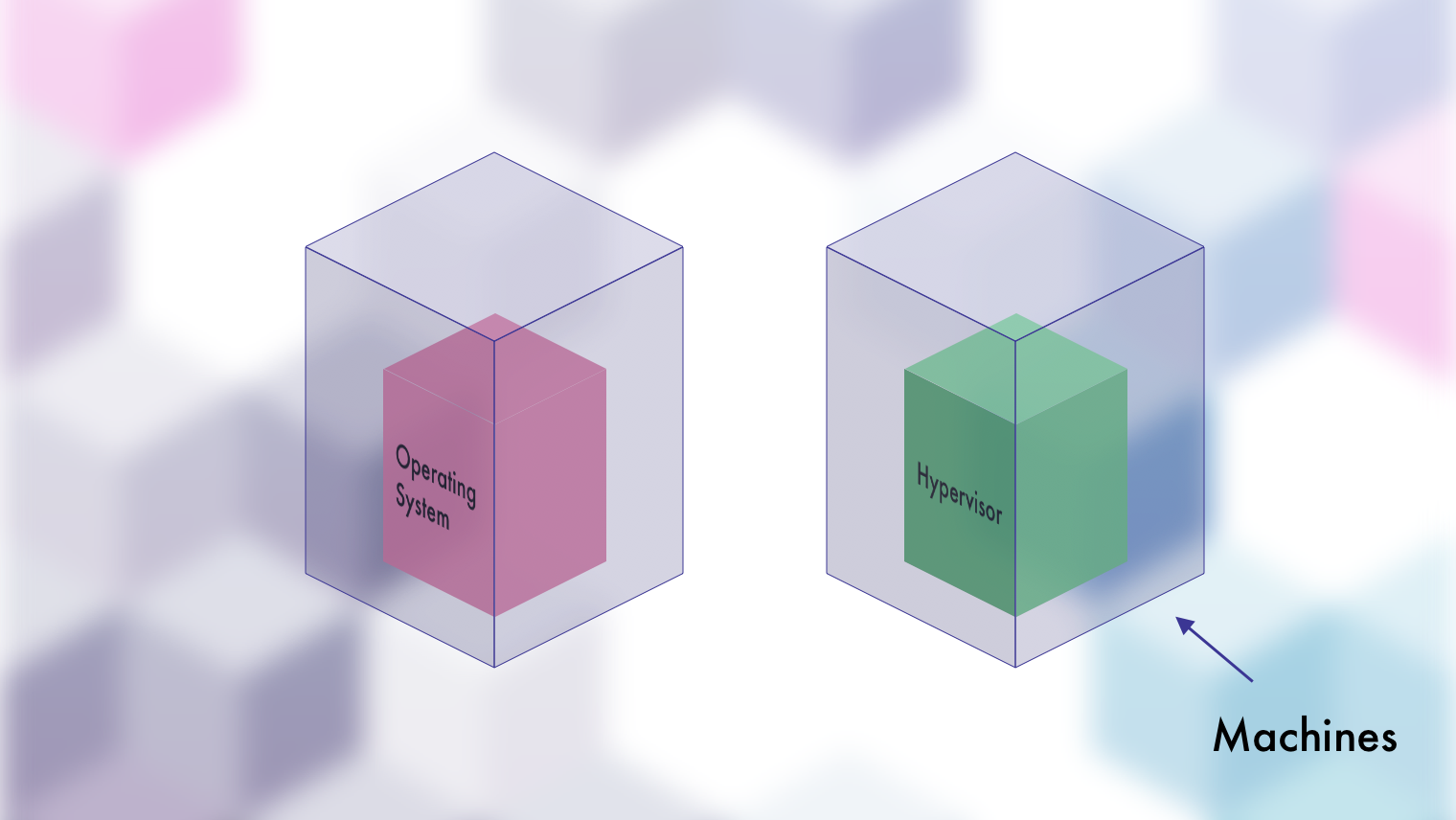
Machines
The original gangster. The machine itself. Buy it, rack it up, cable it, and plug it in. At this point you've got three options:
- Throw an operating system on it directly.
- Throw a "hypervisor" on it so that you can make multiple "virtual machines."
- Do #1 and then do #2 on top of the operating system.
If you're sitting at home, you're more than likely working with option #1. If you're talking about your company's infrastructure or a cloud provider, it's more than likely #2 or #3. For the rest of this post, we'll talk about everything in context of #2.
It's important to remember that this is the beginning for everyone. For personal computing. For company data centers. For massive cloud providers. It's easy to get lost in the sea of terminology and believe that there's a literal cloud upon which angels and devils distribute cat pictures.
"What's a virtual machine?"
We'll talk about that next.
"What's a hypervisor?"
Let's revisit this question after we talk about virtual machines. Speaking of which...
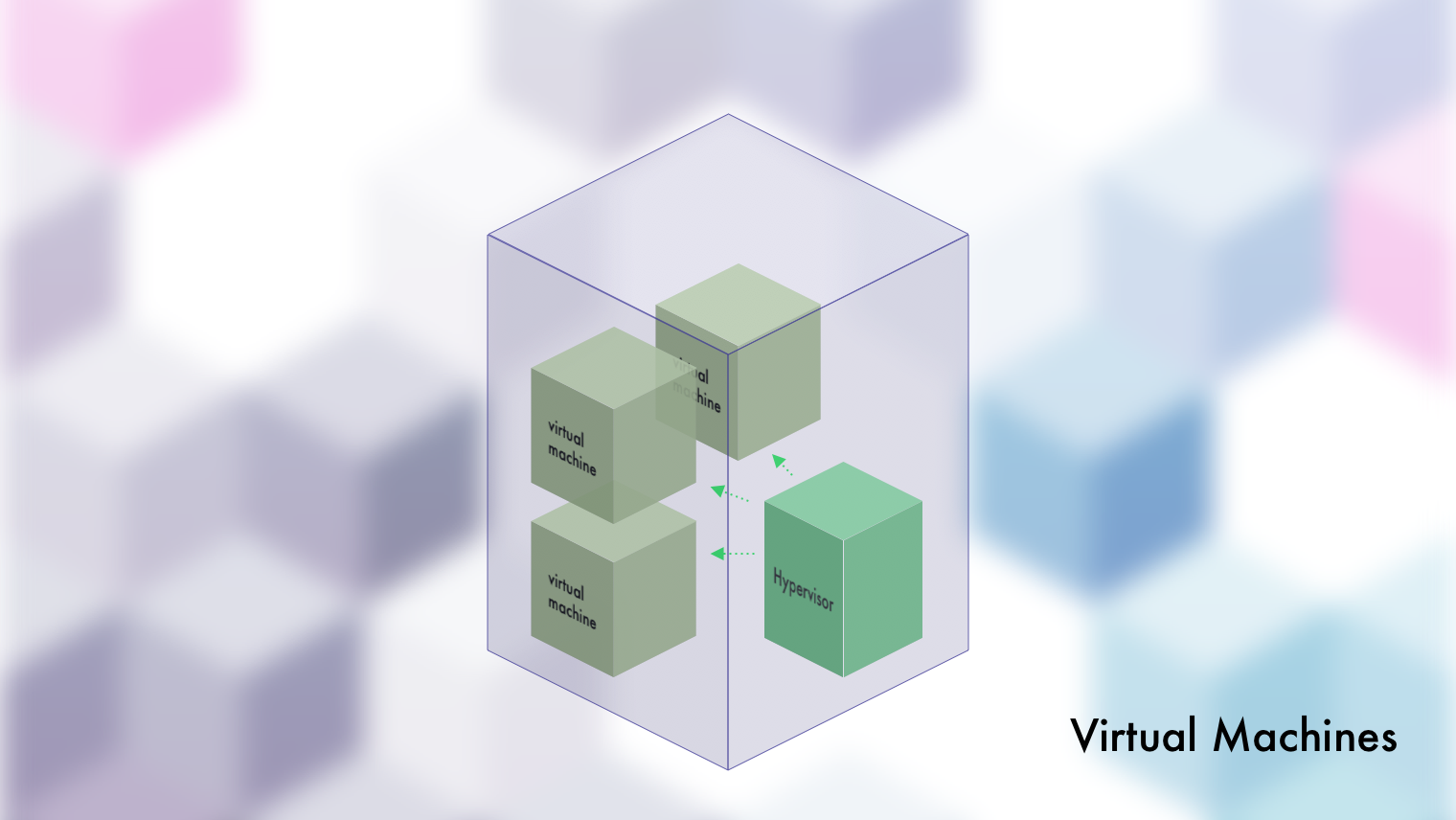
Virtual Machines
From a practical standpoint, it's creating completely separated machines...in your real machine. Obviously they're not REAL machines, which is why they're called "Virtual Machines" and often referred to as "VMs" for short. But from their standpoint, and yours, they may as well be a real machine. They get their own operating system, file system, resources to work with...the whole shebang.
When you spin up "servers" on any cloud provider, this is what you're doing. You're making a virtual machine on their real machines. This is useful because it lets you make better use of the real machine's resources. Think about it, at any given time, how much of your own computer's resources sit idle? Probably a good amount. For your own computer, no big deal. For a company spending dollars? 10 consultants and a partridge in a pear tree.
Virtual machines, or VMs, let us use up a real machine's resources rather efficiently while also giving us a secure separation between them. Meaning that if we have a real machine called Bob, and on it there are two virtual machines called Beth and Brody...neither Beth nor Brody will be able to affect each other despite being on the same machine. This is called solving the noisy neighbor problem, which I have yet to figure out in real life.
This separation not only helps line the various cloud providers' pockets, but it lets us deploy applications in entirely isolated environments. You can spin up virtual machines relatively quick (as opposed to real ones), and have a clean slate for whatever you're deploying. That means your old MAMP installation won't be getting in the way.
"Cole, you said you'd tell me what a hypervisor is..."
If your computer's resources (CPU, Memory, etc) are the family TV, and virtual machines are children fighting over who gets to use it, the hypervisor would be the person telling the kids who can use the TV and for how long. Surprisingly, hypervisors date back to the 1960s when IBM was seeking to allow multiple users to use their massive mainframes simultaneously without stepping on each other's toes. Nowadays, hypervisors like Xen and KVM are used to create and manage EC2 Instances on AWS.
"So how do you use a hypervisor...?"
Given a new machine, what do you do first? Probably set up an operating system. Well, instead of installing an operating system, you'd install a hypervisor. However, instead of being able to play games, listen to music, etc, the hypervisor would give you an interface through which you can create and manage virtual machines.
"Wait, so what is VirtualBox?"
So that's technically a hypervisor as well, but it's known as a "type 2" hypervisor. This is where the hypervisor runs on top of an operating system instead of directly on the machine. As you can deduce, this means they're less efficient. But, it also means they're simpler.
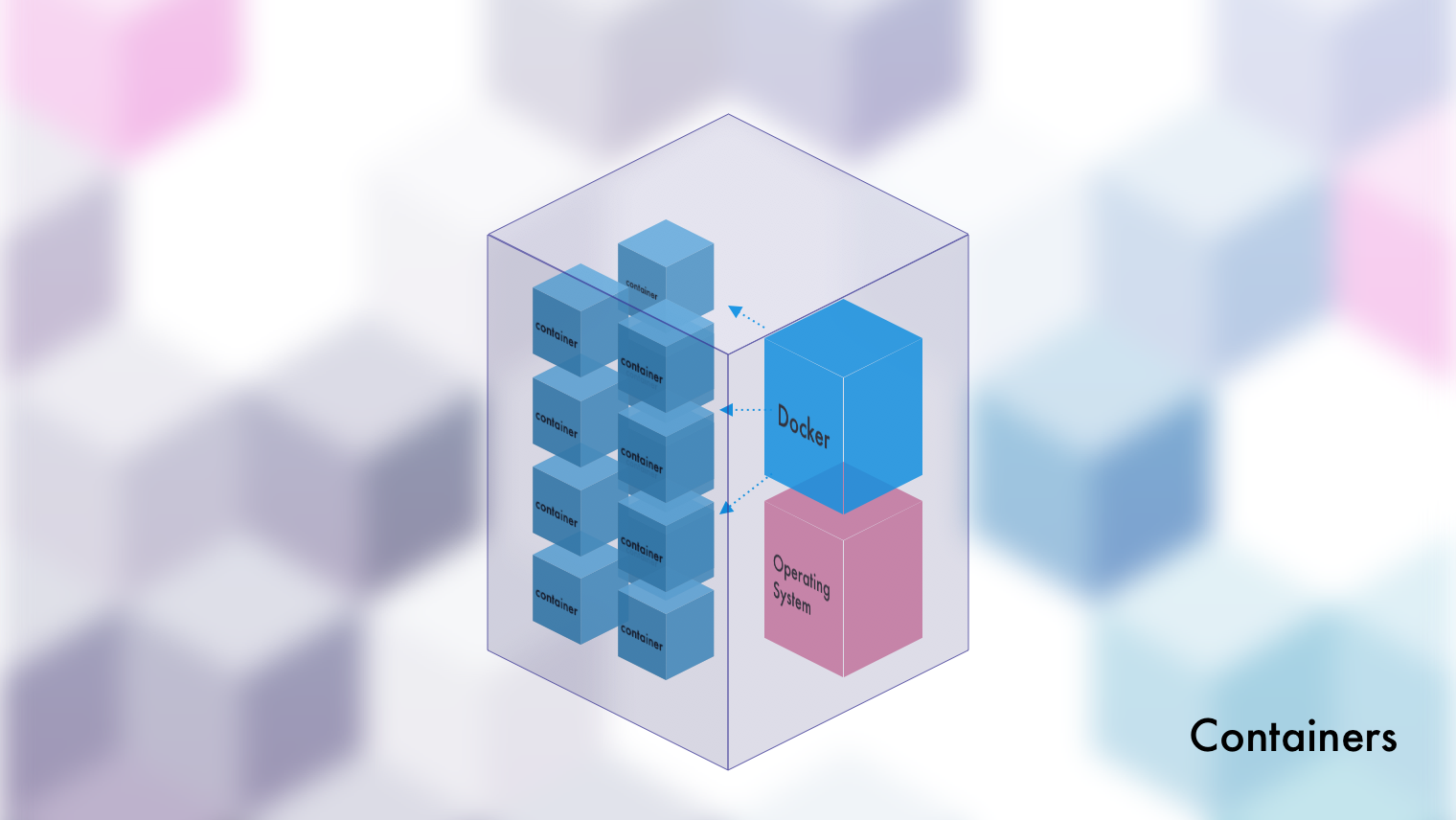
Container Foundations
Although Virtual Machines are incredible at what they do, don't forget that they are basically an entire...machine. Again, this means an entire operating system and all of the other bells and whistles that come with it. For a web application that probably uses a fraction of its machine's resources, that's a lot of wasted overhead. Even if you're using a lightweight Linux distribution, it'd still be like those high-end restaurants that give you 10 utensils, a massive plate, and 20 condiments for a 4-inch slab of meat.
From a practical standpoint, when you spin up a container, it'll remind you of a virtual machine. It will appear to have its own operating system, file system, and whatever else you've included within it. Without digging around, you would once again believe yourself to be in an entirely separate machine. This means, like with VMs, you could install your web application, run it, and open it up to the world. This also means, like with VMs, you get that benefit of efficient resource usage and separation.
But what's different? I know a lot of folks stop at, "well they just use less." Or "they share the same operating system." While those are true, let's talk about how they're implemented.
In the world of Linux there exist two features: namespaces and cgroups. These are the primary building blocks of containers. What do they do? Well, first, although I'm sure this is known...remember that a "process" is just an instance of a running "program." A program is just the instructions. A process is when you take those instructions, give them computer resources, and let them do their thing. Since they're all sharing either their real machine or virtual machine's resources, it also means that they can communicate with each other. So what do these two features do?
namespaces allow you to group a set of processes and, in essence, limit what they can see about the machine they're on. For the purposes of containers, it comes down to making the processes, grouped in a namespace, believe that they're alone in the universe. This is good because it means isolation, much like with virtual machines.
cgroups on the other hand allow you to take a set of processes and limit what resources they can use on a system. This means you can, for example, allocate only a portion of Memory and CPU to a set of processes.
Hopefully you're catching on, because this is the foundation of containers. We pack up a set of processes, make them think they're alone, and limit the resources they can use. Boom. Contained.
Given what we've just talked about, their "lightweight" nature should make more sense. They share the same operating system and machine's resources instead of having their own.
"But, when I dive into my container, it's got a different operating system!"
Yes, it has enough of that operating system to run. And that's the way to think about containers. Virtual machines have everything to be treated like a real machine. Containers have JUST ENOUGH to run whatever it is you want to put in them.
BUT. IN PRACTICE AND PLAIN ENGLISH. It's going to seem a lot like creating a virtual machine. But they'll take up less space and allow you to pack more of them on any given machine. This means you can make more use out of your hardware, since again, your web app more than likely doesn't need an entire virtualized machine. It needs just enough to do its thing, and that's what a container will give you.
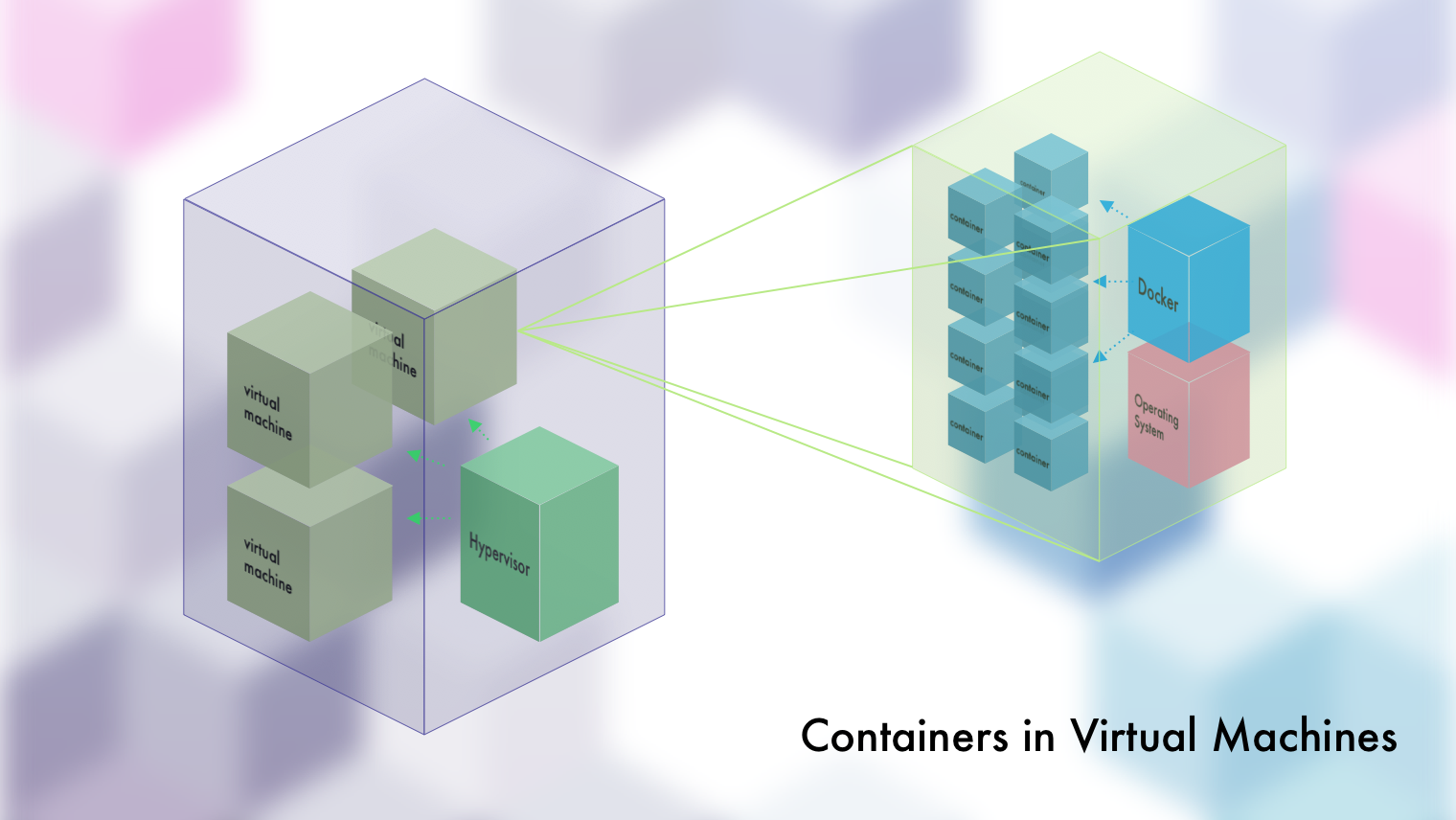
And by the way yes, you can and will often run containers IN virtual machines. And why? Aside from those more-or-less being the only thing you can set up on a modern cloud provider...they also give the same benefits as running containers in real machines. In a virtual machine, given X amount of CPU, and Y amount of memory, those resources are probably NOT being fully utilized. By using containers ON the virtual machine, once again, we make the most of limited resources while still achieving safe separation.
It'd be like, instead of throwing all of your stuff in one big box (VM), putting each thing in its own perfectly sized box (container) first. You'd be able to make even MORE out of the big box (VM). And of course the big box (VM) sits in your house (real machine), separated from other boxes.
"Wait, so how am I running Docker on my Mac/Windows...?"
They're spinning up a virtual machine in the background with Linux on it and putting Docker on that. When you interact with Docker, you're really interacting with Docker INSIDE of that virtual machine. This one concept is probably the source of most of your local Docker errors.
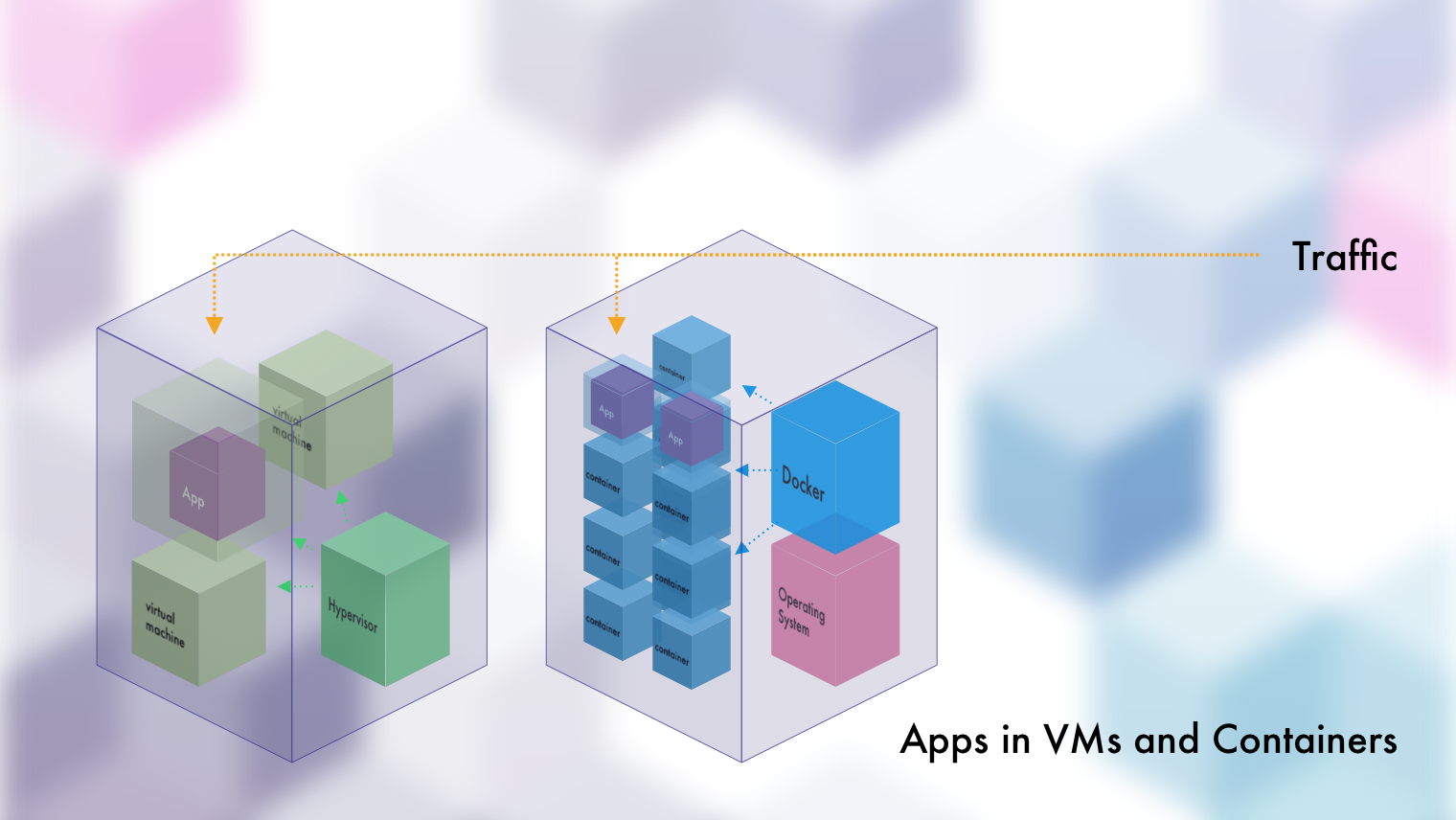
Running Applications in Virtual Machines or Containers
This is a lot of damn work to get that Python app up and running right? Well, thankfully most of this is abstracted away from us in on a day-to-day basis. Generally we'll spin up the VM on something like VirtualBox or a container on Docker. From there we'll get our application up and running, expose the VM or the container to the real machine it's running on...and then folks can connect to it and see your newly minted cat photo application.
"But Why...?"
I know we've talked about many of these things in passing, but just to summarize the benefits of both VMs and containers:
- They take up less space and let us make better usage of the hardware we have.
- They're separated from each other.
- They're a clean slate for our applications to run on.
- They can be created and destroyed with little effort (though containers take even less).
This also leads us to the incredible idea of "immutable infrastructure." That means that every time we need to deploy a new version of our application, instead of finagling with an existing machine, we can make a brand-new virtual machine or container with the new version of the app. This means no more dependencies fighting with each other, no more disrupting other services running, and likely less sleep deprivation for the operators and developers.
But even if we DO get an application or virtual machine up and running with our application...how do we make more of those? Because although that one tiny VM is going to do okay for a while, eventually it's going to need some help when more users start using the application that's on it. The same holds true with containers as well.
"So how do I run a virtual machine on AWS or GCP?"
Again, you don't have to worry about that there. If you spin up an "instance" on either of those, you ARE creating a virtual machine.
"How do I run containers on virtual machines?"
The same way you would on any other machine. Download and install a container runtime like Docker. Run containers.
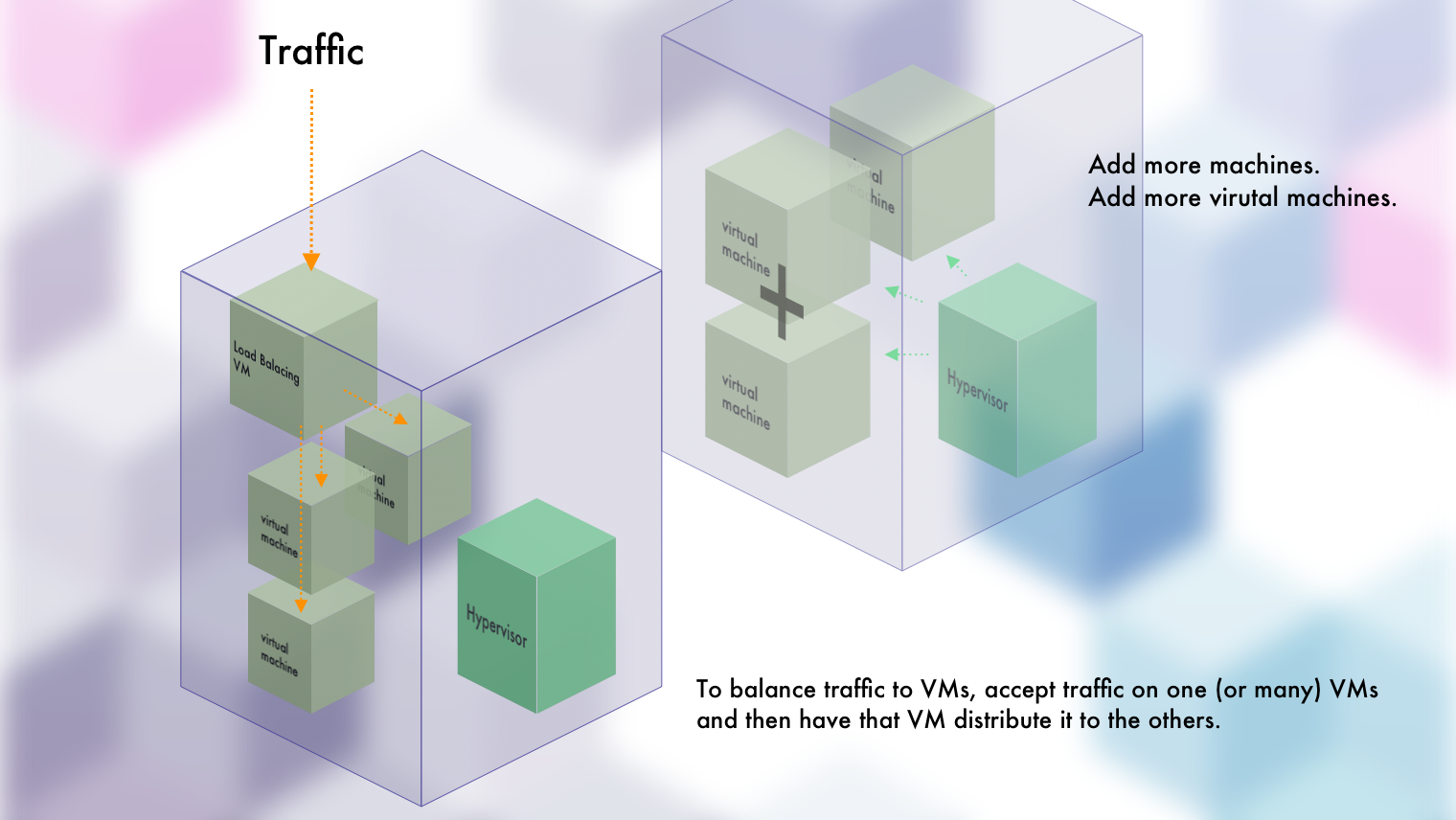
Scaling Out and Managing Virtual Machines
As we talked about in our Servers, Server Fleets, and Databases post, on the typical cloud provider, scaling out virtual machines isn't all that difficult to do. We won't go into how you'd do that on your own hardware in order to avoid slipping down the tip of an iceberg into the cold depths of an infinite scroll. I'm only going to touch on it lightly, because in order to understand container orchestration, we need this context.
Because real machines are abstracted away from us on cloud providers, we can think of the virtual machines as if...they were real machines (only to simplify thinking). They all get their own resources, IPs, OS, etc. Because of this, how would you scale out a set of real machines? By making one (or some) machines responsible for delegating incoming traffic to other machines that are hosting your application. Yep. And that's load balancing.
What if you need to update the applications or the virtual machines themselves? Though there's a number of ways to do so, the simplest pattern is to spin up the brand new VMs with the updated application, point traffic to them, and then get rid of the old machines/versions.
What if one of the virtual machines goes down due to faulty developer code of operator configurations? Well, again, if you're on one of the major cloud providers, their services will spin back up another virtual machine to take the dead one's place.
These "things" that take care of spinning back up VMs, scaling them out, pointing traffic to them, scaling go by different names in the major cloud providers. In AWS they're known as Auto Scaling Groups. In GCP they're called Instance Groups. Of course you can do it all manually with your own scripts, cloud provider APIs, and/or other tools (Ansible, Chef, Puppet, etc), and that's perfectly fine as well.
The point of touching on this is that we need some sort of mechanism to help us account for scale, VMs or applications dying, and letting users reach the applications they're trying to use. In jargon these features are known as scalability, fault-tolerance, and service discovery. It's largely dealt with and well thought out in the world of virtual machines. But what about containers?
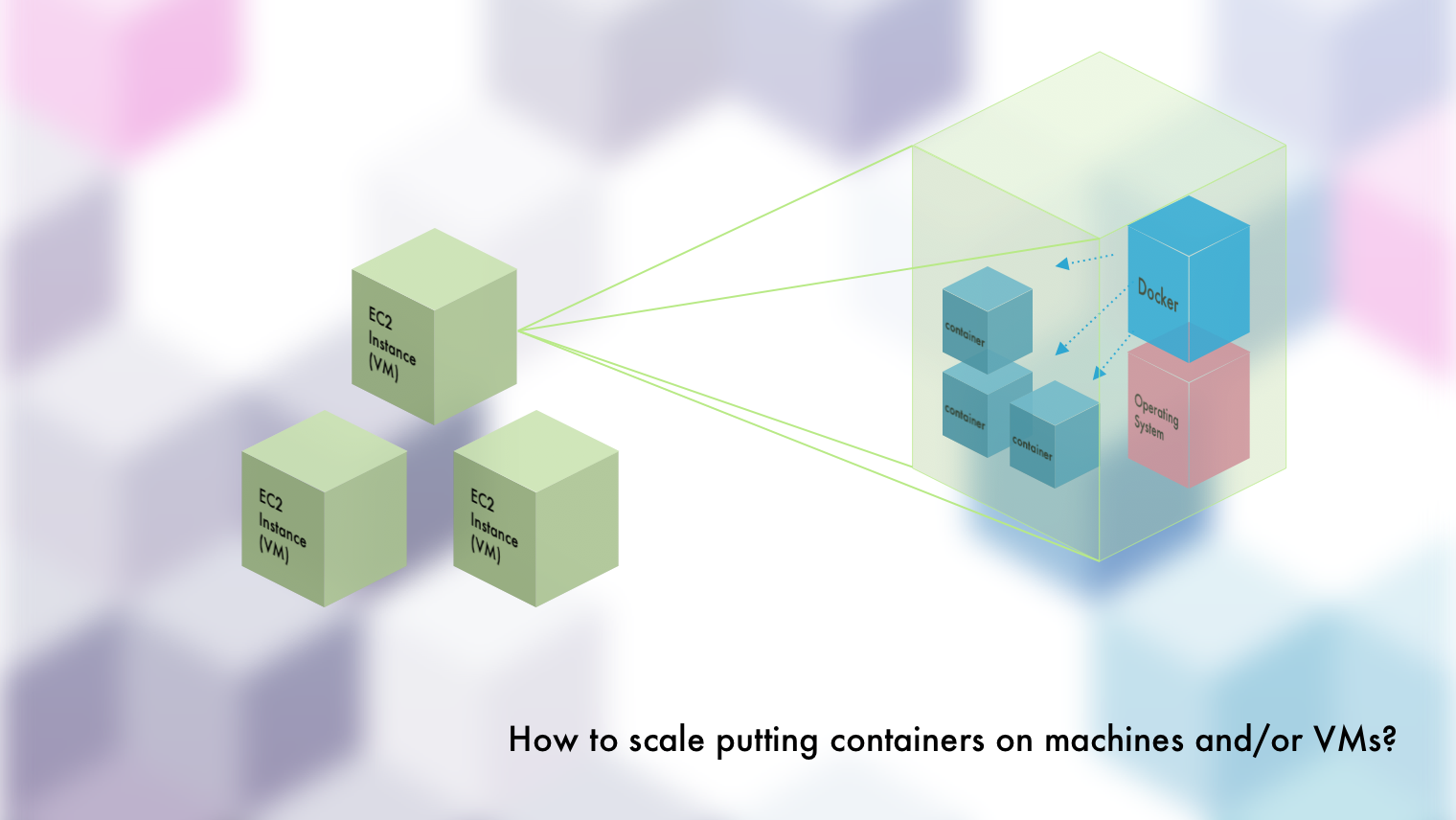
Scaling out and Managing Containers
So you create a container and put your application in it. It's in a nice, isolated package that has everything it needs to run whatever it is you want it to run. You can open it up to the machine (virtual or real), and in doing so, allow others to access it.
Let's say that we've created 3 EC2 instances (VMs) on AWS. Each of them has more CPU and memory than will be practically used by any one instance of our application, or any other apps we might launch for that matter. Although the question at that point might be, "well, can't we just get a smaller instance?" just know that those things can only get so small.
Given our 3 EC2 instances, we go and set up 3 containers on each of them. Each of the 3 containers is a different application and given limited resources (CPU / memory). This enables us to take full advantage of the instance's (VM's) resources. And now we have some questions to ask ourselves...
Do we really want to set these containers up by hand each time? Sure we could write custom scripts, surely there's a well defined pattern.
How are we going to give the outside world access to these containers?
What are going to do if a container dies? How will we even know if the container dies?
How will we add more containers if the existing ones can't handle any more traffic?
How will we add more containers if we add more virtual machines to host them? Without manually setting them up that is.
How can we let containers interact and communicate with each other? i.e. if you have two that help each other.
How do we monitor the status and metrics of any given container?
Well my friend, we've FINALLY stepped into the realm of Container Orchestration!

Cluster Scheduling and Management
...Well almost. Although not exclusive to container orchestration, we need to talk about Cluster Scheduling and Management. And to do so, first, let's roll back to where we were talking about scaling out virtual machines.
For most applications, again, the pattern is pretty straightforward:
- Have a bunch of (virtual) machines that host your application.
- Have some machines that receive the traffic and delegate it to the machines with the applications on them.
Although the machines balancing the load of traffic are aware of the machines with the applications, the relationship doesn't extend much past that. How do we know which machine is best suited to receive more traffic? How do we know how much CPU, memory, etc is being used across all of the machines? As things are, it's very one-way and very independent. Yes, we can make the machines bigger and we can add more of them, and indeed this will allow us to handle more traffic. But this would be like having a bunch of employees that work for you but know nothing of each other, can't share their knowledge, and never show up to company outings. Furthermore, they're not being used to their full capacity.
So your cat photo application is taking off and you decide you need an image processing service to help detect and remove dog photos. Well, one idea would be to just bake the image processing functionality into the same application. However, if the image processing portion is a resource hog, and you have to scale out because of it, you'll be scaling everything in your application. But in reality, you just need to scale out the image processing part.
Okay, so then you decide to separate out the image processing part into its own application. What to do now? The cat photo app still needs to interact with it. Yes, you could throw it on an entirely new set of machines and use the exact same setup as you have for the cat application. However, you know that there's extra, unused compute and resources on your existing machines. Why not just reuse those? Furthermore, why not get rid of all the extra barriers and make interaction between them easier?
Well, you can! But not with any real ease if you take the manual route. If you're going to start putting things on the same machines (virtual or real), well, you encounter all of the problems that containers set out to solve. Clashing dependencies, resource usage from one app affecting the other, pointing traffic to the different applications, monitoring their status, allowing them to communicate with each other...and you've got to do it across however many machines you have. Containers didn't solve this problem first, they're just a newer approach to it.
With respect to solving this problem with only real and virtual machines, this is where the concept of Clusters come into play.
What's a Cluster?
A cluster is where you take a bunch of separate machines (virtual or real), and group and set them up in such a way that they can be treated as one big machine. A cluster generally consists of a set of "master" machines that oversee and coordinate "worker" machines that do the actual work.
So when folks talk about a "Hadoop" cluster, they're talking about a set of machines, working together as one, to process lots of data. When people talk about Apache Mesos, they're talking about a set of machines, whereby many applications and services can be deployed to it, managed, and of course, made available to users and other services.
Because think of it. Why do we add more machines to our architecture? Because we're running out of resources. And what's difficult about that? Managing all of the different configurations, making related things talk to each other, monitoring them, etc. Why don't we just stick to one machine? Because they can only get so big. Also, if that one big machine fails, we're probably in deep trouble.
Again, the simplest way to think about clusters is that it lets you treat a whole group of machines as a single machine. Working with a single machine is far simpler, because it's easier to monitor, make services running on it talk to each other, and make the most of the machines that you have.
If we think about our earlier employee analogy, a cluster is like a manager of the employees (VMs or real machines). It gives them enough work to where they're at capacity, but not too overworked. It helps them coordinate their efforts to accomplish larger tasks. It monitors performance and fires / hires employees when needed. It gives us owners (developers / operators of the cluster) a far simpler way to communicate what we want done.
"What is Cluster Management and Scheduling then?"
Pretty much what I just described. The "cluster" is the fact that they're all linked up and treated as one. The scheduling part is giving each machine in the cluster the right workload. The management part is monitoring the various machines, adding / removing them, and any other administrative tasks.
"This is starting to sound anti-monolith..."
Look friend, the great part about containers and VMs is that we don't really have to worry (as much) about what's in them. If you want to pack your entire Rails application into one code base, that's perfectly fine. In the end, we're just tossing it in a VM (or container), and trying to make the most of the machines that we have. On the other hand, if you want to split it up into a bunch of fine-grained services that work together...well, we should probably look at containers first, because dedicating an entire VM to a tiny app isn't all that efficient.
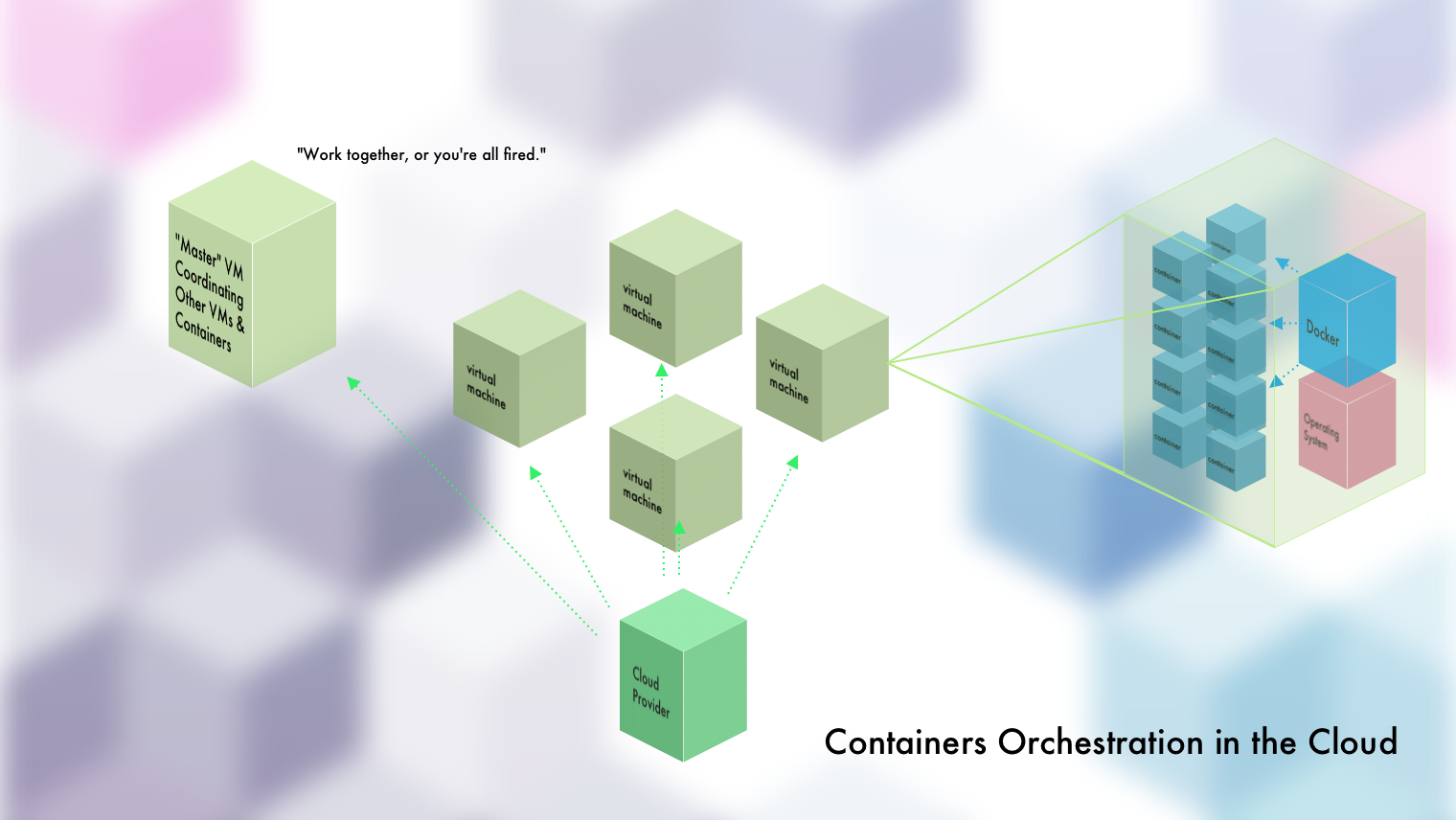
Container Orchestration
AND NOW WE'RE HERE. Okay, so you get clusters, and all of the above. Because of that, we can talk about what things like Kubernetes, ECS/EKS, Titus, Marathon, Nomad, and all of these other container orchestration solutions do. If you've read this far and understood it, then this is simple:
Container Orchestrators turn a group of machines into a cluster that you can then deploy and manage containers on. They automate and streamline things like:
- setting up containers on machines
- making sure machines have enough space for new containers
- keeping a certain number of containers running at all times
- allowing external traffic to reach containers
- namespacing containers into their own, isolated groups
- returning metrics on both the containers and the machines
- enabling communication between containers
If we return to our employee analogy, clusters without containers would be like the manager dumping big projects on each employee (VM or real machine). But clusters WITH containers would be like the manager splitting up all of the projects into smaller tasks that can be better split amongst employees. This makes it easier to make the most of your machines for the same reason that Tetris would be dumb-easy if every tetrimino was a single block (as opposed to the L-shaped ones).
"Okay, but Cole, this seems like a lot of work and thought?"
As with anything, the benefit of this complexity doesn't really show itself at early stages. But you have to understand that the reason things like Google's "Borg" came about were not to introduce unneeded complexity. And by the way, "Borg" was the Kubernetes predecessor. The idea was to make it so that developers could focus on building their applications, saying what resources it needed, putting this info in a file, submitting the file, and moving on.
"How is this less complex...?"
If I give you 5 applications and say, "go forth, host these, make them able to communicate with each other, and for e-god's sake make sure Jerry's code doesn't bring the whole system down.." How would you do it? What happens if you need another application?
On the other hand, when you have a container orchestrator all set up and ready to go...adding new applications is as simple as...
- Making a new Docker Image (assuming you're using Docker)
- Defining the specs / requirements of your container and app
- Telling the container orchestrator about it
- Done
Whichever orchestrator you're using will then worry about putting it on the machine that has enough resources to handle it. It'll return to you metrics about it. It'll let it communicate with other containers, if you've allowed that. It'll keep a specified number of containers alive at all time. It'll deal with adding new machines to your cluster and allowing them to host more containers.
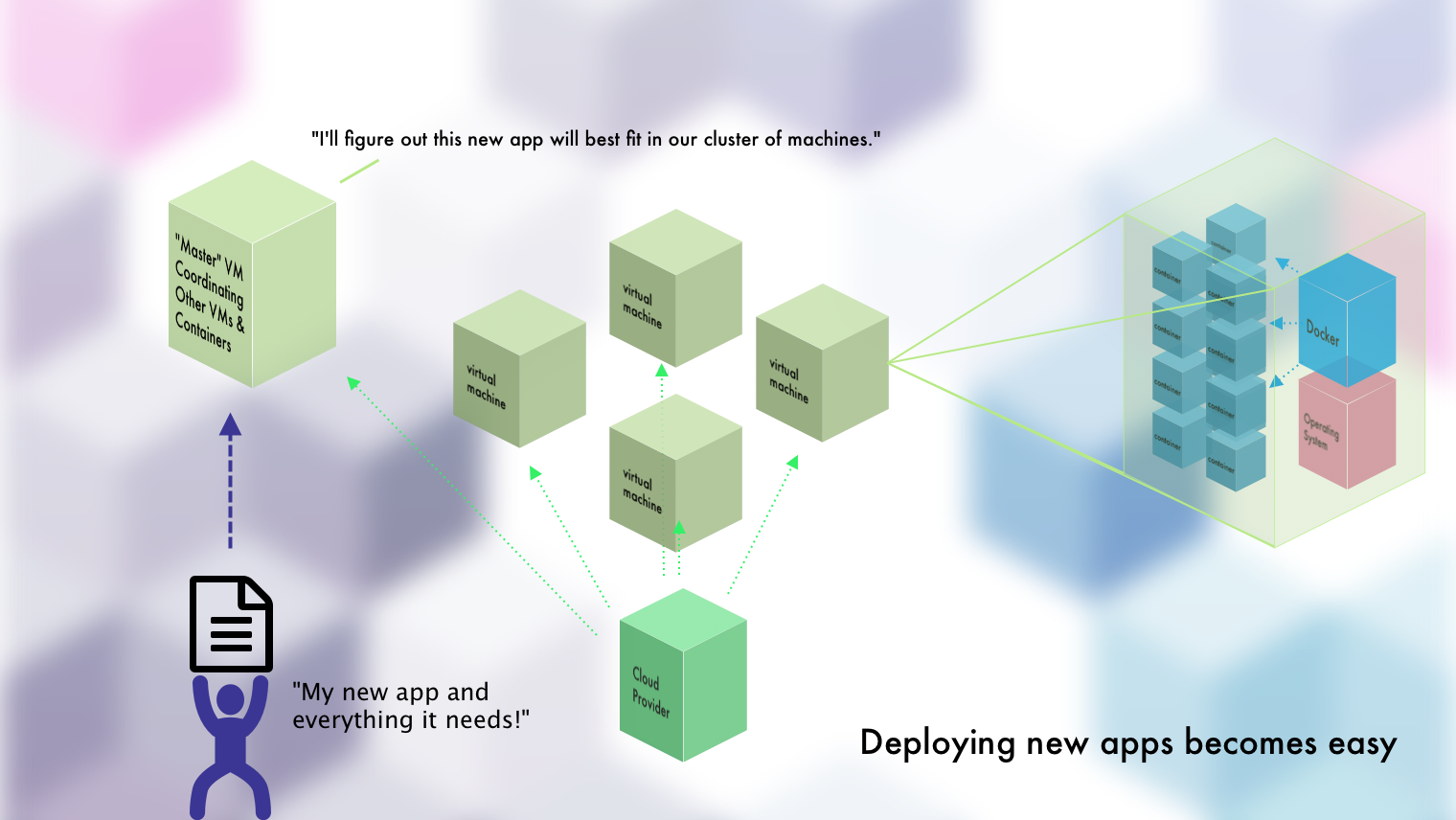
It's almost as if you get your own personal Heroku. You stop having to worry about all of the underlying details and, instead, can let developers simply deploy applications and services. The operators can also stop having to worry about dealing with faulty code and resources management since containers are isolated and only take up the resources that they need (assuming they've been well-defined, nothing's stopping you from including everything and the kitchen sink in your containers).
In terms of work investment, it's good to think of it like a production factory. If you're making and selling ice-cream sandwiches...sure it's super simple when you have a small customer base. But when you need to sell millions? Yes, setting up a factory for the first time is going to be a massive pain and financial investment. However, once it's up and running, it's FAR simpler to produce those millions of ice-cream sandwiches.
"Cole, which orchestrator?"
No, no. Not in this post. I will give you my take on them though - they're a lot like programming languages. You can more than likely get done what you want with any of them. Yes, some are better suited for certain scenarios. No, they're not worth the ideological war that can take place when discussing the options.
"Either way, this sounds like a lot of work to get one app up..."
I won't say that it's not NOT a lot of work...but it's not a ton of work if you know what you're doing. The thing to keep in mind is that you can set all of this stuff up on a handful of servers. If you're deploying your application for production usage, you're more than likely doing that anyway. Getting a container orchestration solution set up just gets that work done upfront.
That said, I will say that whether or not you do this should be a business decision. If you've got product-market fit, customers are rolling in, scale is pretty ensured...well yes, I think it's a great upfront investment. However, if you have no idea if the company, and its product, will be around a few months from now...probably not. Unless of course you've figured all of this stuff out to the point where you can set it up just as fast.
That was a long journey...
Indeed. We've come a long way my friend. Like many things in technology, in order to truly understand the entire picture you have to be willing to dive beneath the waters, beyond the tip of the iceberg. Though container orchestrators are the current peak of this glacial mountain, they're but a fraction of the hard work, innovation, and technology upon which they stand.
Other Posts in this Series
Check out the rest of the posts in my Understanding Modern Architecture on AWS series:
- Understanding Modern Cloud Architecture on AWS: A Concepts Series
- Understanding Modern Cloud Architecture on AWS: Server Fleets and Databases
- Understanding Modern Cloud Architecture on AWS: Docker and Containers
- Interlude - From Plain Machines to Container Orchestration: A Complete Explanation
- Understanding Modern Cloud Architecture on AWS: Container Orchestration with ECS
- Understanding Modern Cloud Architecture on AWS: Storage and Content Delivery Networks
Enjoy Posts Like These? Sign up to my mailing list!

J Cole Morrison
http://start.jcolemorrison.comDeveloper Advocate @HashiCorp, DevOps Enthusiast, Startup Lover, Teaching at awsdevops.io