Understanding Modern Cloud Architecture on AWS: Server Fleets and Databases

Table of Contents
- Introduction
- Servers on AWS: EC2 and its Instances
- Separating the Database: RDS and Aurora
- Server Fleets: Tackling the Scaling Issue
- Load Balancers: Directing Traffic
- Conclusion
- Watch Instead of Read on Youtube
- Other Posts in This Series
Introduction
Welcome to part 2 of the Understanding Modern Cloud Architecture on AWS blog series! In the last post we discussed the approach we're taking to learning all of this stuff, what you need to know, and what types of software this architecture works for. We also dove into what makes a productive development environment and went through some suggested technologies to use when creating it.
(If you missed part one, you can read it here.)
So what's next?
Well, let's imagine that our team has been pumping through features with our super-charged development environment and that, between this post and the last one, they've finished the application. They've had to rotate through 3 agile coaches and 2 scrum masters to make it happen, but it's done. Now we need to make it live. HOW we do that is the topic of this post.
Servers on AWS: EC2 and its Instances
The two primary pieces that are going to let us make our application live are (1) servers and (2) databases. A server to host our application on that allows users to connect to it and a database to persist the data.
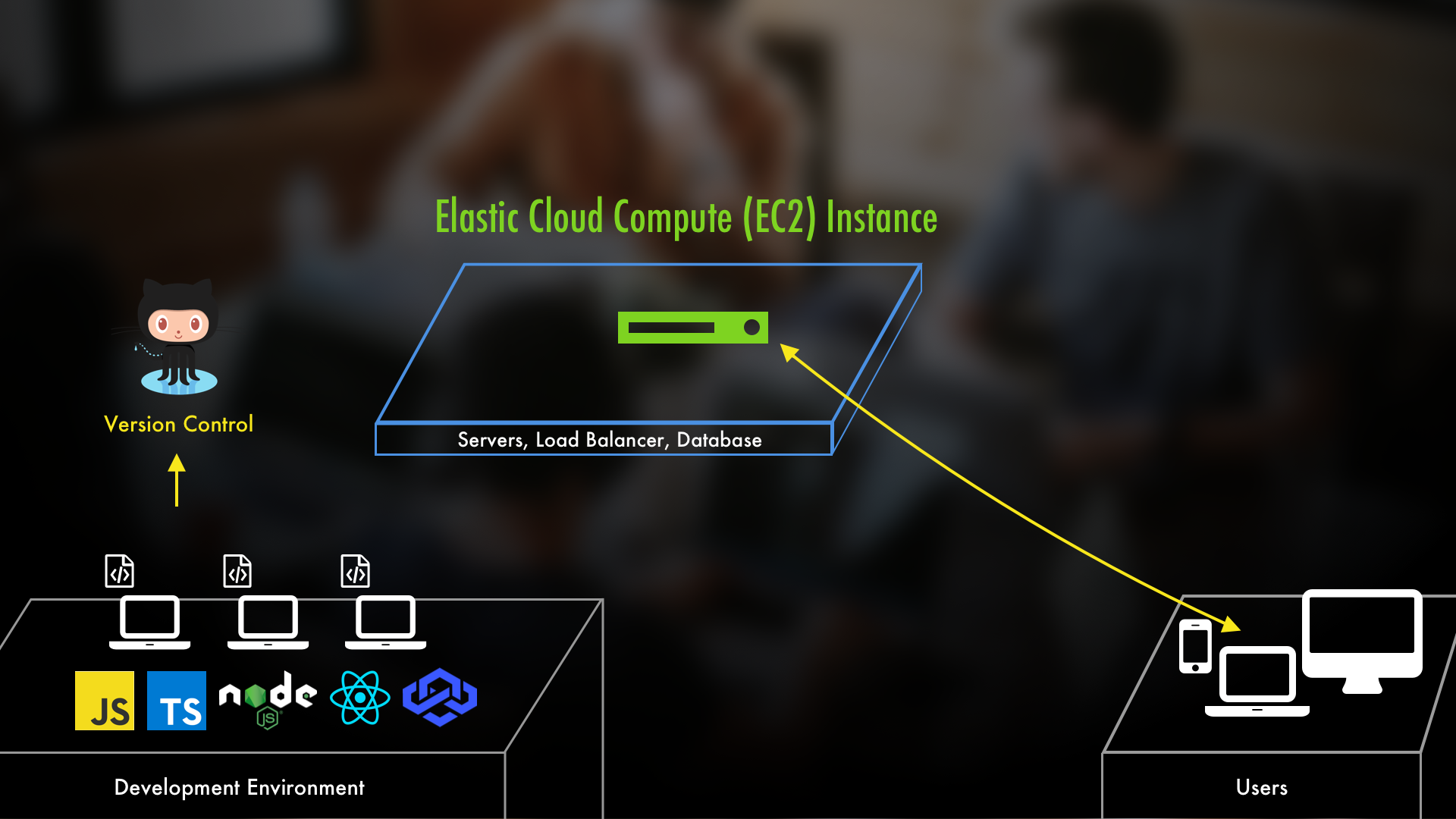
In AWS, the way we create servers is through their Elastic Cloud Compute service, also known as EC2. It's in this service that we can pick settings for our server like an operating system, CPU power, memory levels, and more. After we've selected all of our settings, launching the server is as simple as clicking a couple of buttons. A server created through EC2 is known as an "EC2 Instance". Yes, if you're familiar with AWS on any level that won't confuse you. But, I bring it up because you'll see the word "instance" and "server" interchanged quite a bit when in the AWS sphere, including in this post.
(Quick aside, if you'd like to learn more about EC2, I have my EC2 Fundamentals Series up on YouTube. It'll tell you all you need to know about EC2 to make servers and start working with them by creating a Node.js based web server.)
Once this server is up, you can put your application on it. Now, if you're not familiar with working with servers, they can be pretty intimidating. A lot of developers I know, when they visualize servers, see those big server farms with racks of boxes and imagine themselves messing up so terribly that Morpheus appears and dropkicks them in the gut.
But in reality, an EC2 Instance isn't even a real machine. It's a virtual machine. So any servers we create are actually isolated virtual machines sharing space on AWS's REAL hardware. In a nutshell, virtual machines (aka VMs) are like simulated computers in a real computer. They can have their own operating system, dependencies, etc, but they use and share the resources of the real computer. Admittedly, that may sound more intimidating...and virtual machines are their own information rabbit hole...
..but look - the simplest way to think about an EC2 instance, or any cloud-based server, is this:
It's still just a computer. Just someone else's. (In this case, it's AWS's.)
You still log into it, set your things up, and do whatever you want to it like you would with any other computer. You make an EC2 instance (aka server) and set up your application on it much like you would on your own computer. The only thing that might get in your way is the operating system. And by the way, the best operating system, for modern high-traffic servers, is Linux. Linux powers 96.3% of the top 1 million domains for a reason. If you don't know Linux, well that can be a hurdle because of how intimidating it can be if you've never used it.
BUT. Let's pretend that you provision an instance and, for whatever reason, it has Windows installed on it. Would setting up the application on it be intimidating now? No, probably not. After all, it's just Windows and you've been using that for a while. The only thing that'd change is, instead of making the application available over localhost, you'd need to make it available to the web.
In the end, that's all you're doing when you provision a server and put your code on it. All the fun tools and automation scripts just remove the manual process. But, if you think of it as "just another computer", it's a lot easier to wrap your head around how to approach it.
And so, you'd grab and install the application from your version control source, which in our case is GitHub. Then you'd make sure the application has all of its dependencies. After that, you'd set up a database on it and point the application to it. And lastly, you'd start up the application and make sure the firewalls allow in HTTP traffic (assuming it's a web application).
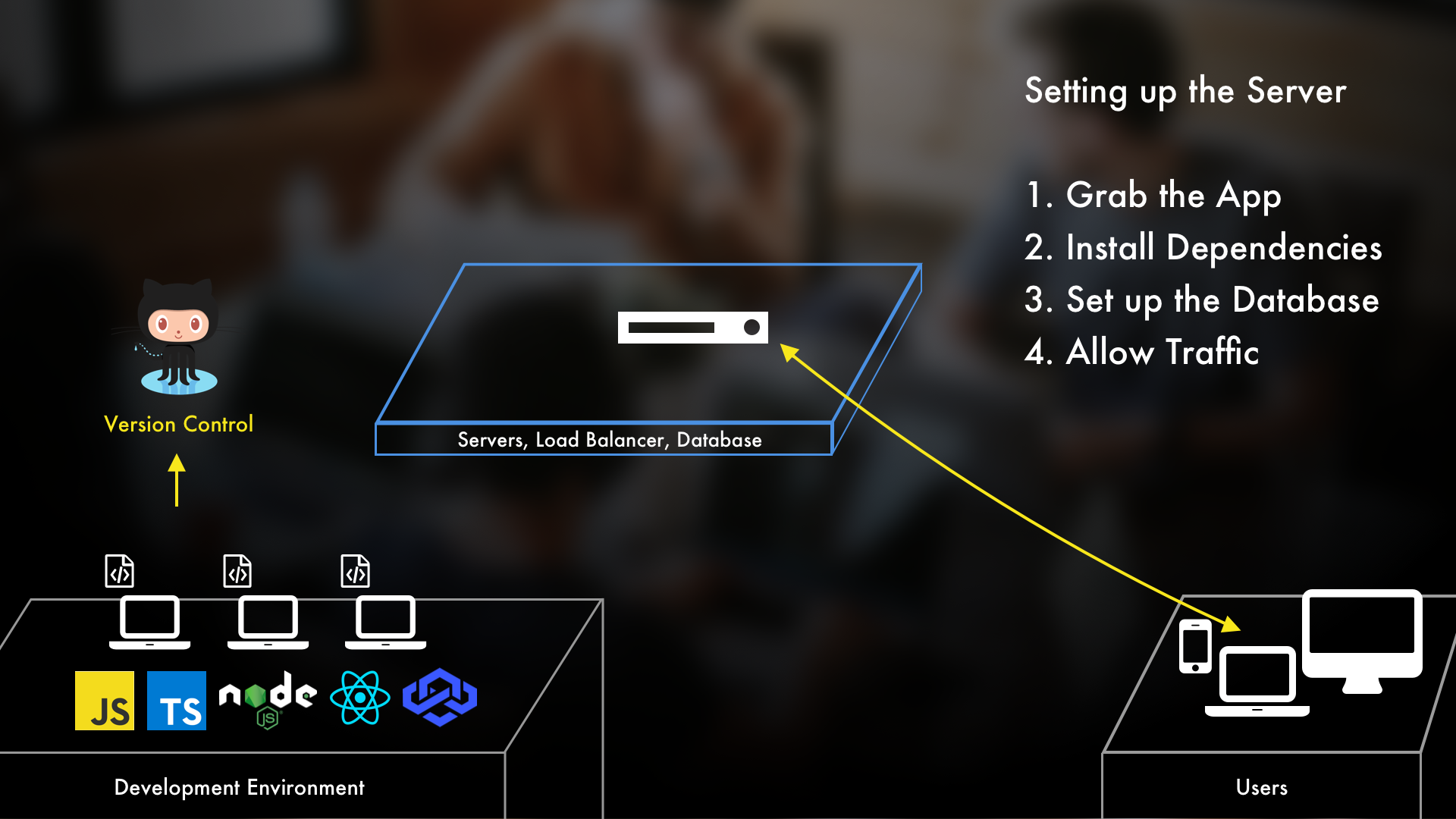
This is what I mean when I say that servers can be unnecessarily intimidating. Because I'd bet a large sum of money that you can do 90%+ of everything mentioned above on your own computer. Again, if you think of an EC2 instance as just another machine, tackling it isn't nearly as bad.
But...
One server isn't going to take us very far. Even if we make this first server (EC2 Instance) extremely big and powerful...databases are pretty weighty. They take up a lot of compute, a lot of storage, and a lot of network throughput. If a server is a house, and the application and database are residents, the database would be hoarding all of the space and making tons of noise. Sure, this works fine for local development. But when hundreds or thousands of users (or more) start coming to the application, that server is going to burn up its resources pretty fast if it's having to handle both the database and the application.
Separating the Database: RDS and Aurora
To deal with the inevitable doom of our one, lonely server, we want to separate our database from our application server. We do so in order to allow our application and database to scale separately. On AWS, we've got two ways we can do that.
The first way would be completely manual - make another EC2 instance (so another server) and put the database on it.
"But how?"
Again, if you think of an EC2 instance as "just another computer" then you'd do so similarly to how you would on your own computer. You'd download, for example, MySQL, set it up, start the database, and allow traffic from your application. Yes, the devil is in the details, but the big picture truly is this simple.
With that done you'd point the application server to the database server, and boom, you're good to go...for now. There's a reason database administration is its own field. There's a LOT to it. Patching, updating, and maintaining a database is a meaty task. So, unless you have an in-house expert or team dedicated to this, you really want to think twice before going the self-managed route.
On the other hand, AWS provides us with their Relational Database Service, also known as RDS.
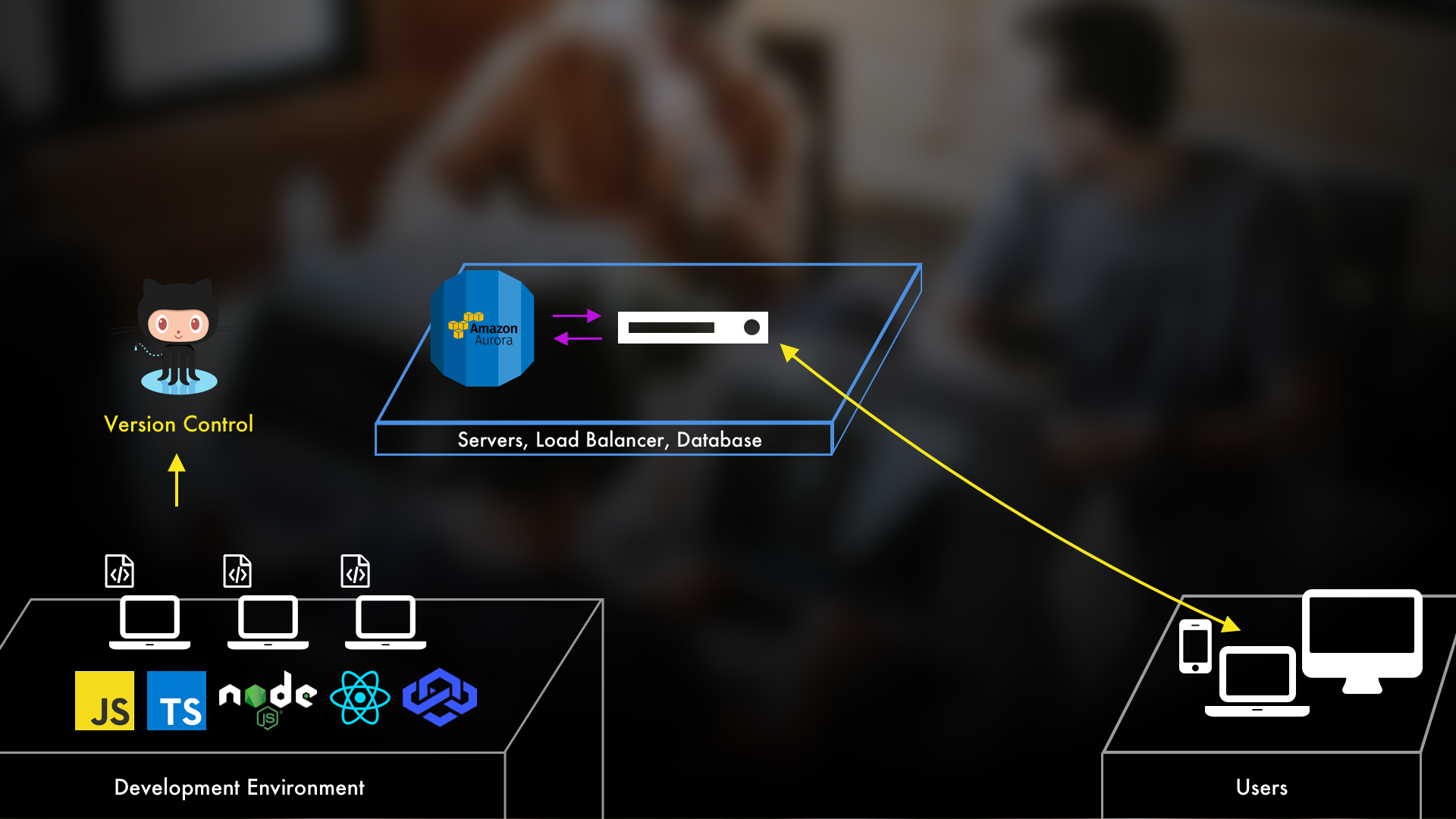
Specifically they have a VERY powerful database called Aurora. It's pretty amazing because it handles all of the scaling, management, and patching for you. It's also directly compatible with both MySQL and PostgreSQL. And so, even if you're developing locally with one of those two, you can still use Aurora when you deploy your application. It's as easy as pointing to Aurora's database endpoint instead of a MySQL one. And, as the RDS marketing team loves to point out, it's five times as fast as MySQL and one-tenth of the cost.
With that, everything would be good to go. Users could hit your server to use the application and the application would interact with the RDS Aurora database.
BUT...what happens if we start getting spikes in traffic? What if our service / company goes viral? Well, thankfully we've got the database side managed if we've picked RDS Aurora...but the application server won't be able to keep up. So we'll talk about how to deal with that next.
Server Fleets: Tackling the Scaling Issue
Now we tackle our scaling problem. Let's imagine that the application has taken off and is getting hammered by tons of traffic. If that's the case our lonely little server isn't going to last long.
So what are our options? Well, we could make the server bigger, and that can be a short term solution. This is called "vertical scaling". And while that can help out in the beginning stages, realize that servers can only get so big. Furthermore, it's just ONE server. If it dies, then everything running on it is obviously gone too. That's not very resilient. And it's a surefire way to get an army of angry users flinging arrows at your social media accounts.
Okay, then what's the right answer? Creating MORE servers. This is known as "horizontal scaling" and allows our architecture to not be bound to the fate of one EC2 instance.
We can do this with what's called an EC2 Auto Scaling Group. Auto Scaling Groups make MANY servers and manages them as a whole. That's really it in a nutshell. And if that sounds oversimplified, it is, but the thing is this: by using an Auto Scaling Group, making and managing many servers is almost as simple doing so with one server.
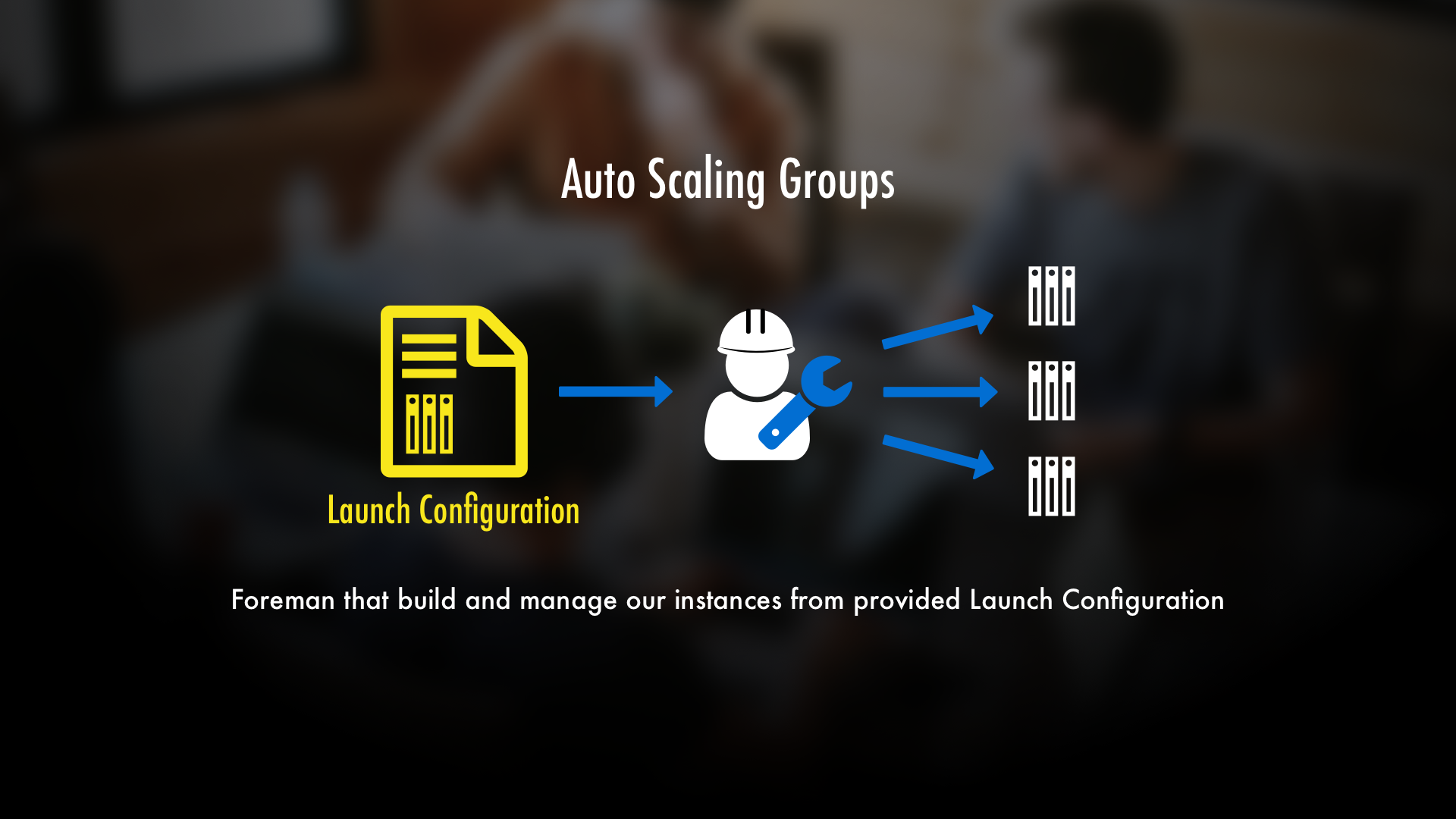
But how do we tell an Auto Scaling Group what type of servers to make? Well, before starting up an Auto Scaling Group you first create what's called a Launch Configuration. Afterwards, you then create an Auto Scaling Group and give it the Launch Configuration. It'll then go and make instances from that template and manage them for us.
You can think of Launch Configurations like a blueprint of an EC2 Instance. If that's the case, then Auto Scaling Groups would be like the foreman that builds and manages the instances using that blueprint. So, not too bad conceptually.
(Quick side note: Even though they're called Auto Scaling Groups, they actually don't automatically scale right out of the gate. They're capable of it, but we'll cover that later on in the series.)
This is great. By using an Auto Scaling Group, we'll be able to make a whole fleet of servers that can host our application. But, with many servers, how do we tell our incoming users which one to go to?
Load Balancers: Directing Traffic
From a data persistence standpoint, we don't really have to worry. Sure, we may have three or four servers hosting our application but they'd all be pointing back to that same RDS Aurora database. What I mean by this is that if we have three servers, Charlie, Dee, and Mac, and one of our users visits Charlie and changes their name, it's not going to prevent them from using our application on server Dee. Why? Because all of our apps are pointing back to the same database. And so, when the user visits the application on server Dee, it'll still be grabbing its data from that same RDS Aurora Database.
If you're catching on, that means we can now spread the load across 3 different servers. However, now we have new problems:
- Where do users connect to?
- How do we preserve sessions?
- And, how do we balance the load automatically?
So, if we have three servers, where do we point our users to? That'd be a confusing conversation. If we have three different servers, they'll all have three different IP addresses. And what about things like sessions? If your application uses session data to keep track of what a user is doing, that's going to be lost if they hop to a different server (assuming they can even figure that out).
And finally, how do we actually balance the load? I doubt users are going to pay any attention to the metrics of your servers and do it themselves. Try selling your product manager on that. Well, this is where...
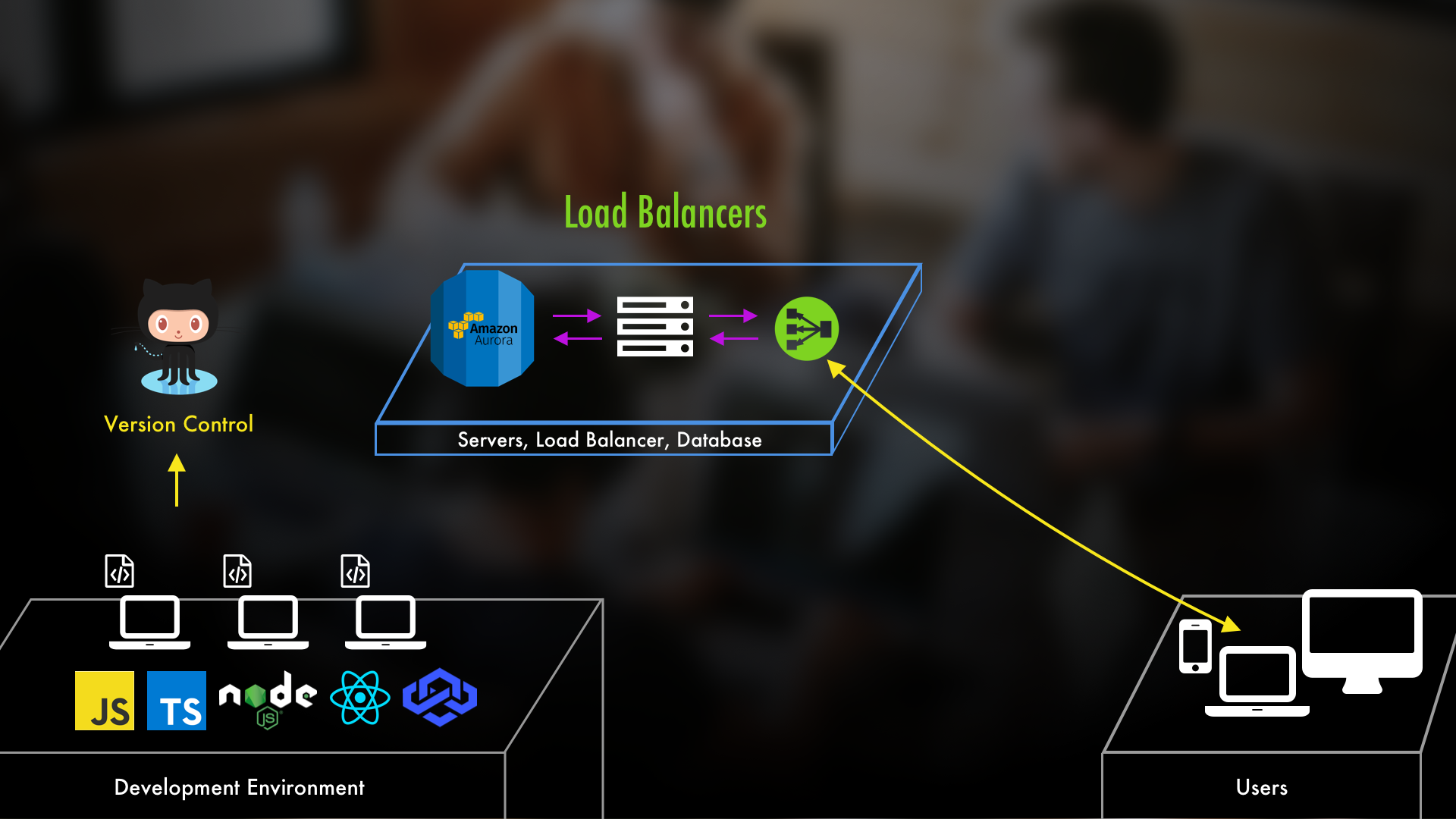
...load balancers come into play. They solve every issue we just talked about and more. Essentially, they accept incoming traffic and then distribute it to the servers that can best handle it.
This may sound like some magical piece of technology. But just like how we could set up a database on a server, we can do the same with load balancers. You just create a server and then use something like NGINX, HAProxy, or Apache. Then you tell those tools, whichever you've selected, about the servers you're trying to load balance traffic to.
That being said, AWS does provide us with their own Load Balancers. In EC2 there's a variety of load balancers that do all of this stuff for us automatically...and, of course, hook up to EC2 instances very easily. They also provide us with a lot of options and features that would otherwise take a hefty bit of work if we wanted to implement that functionality on our own.
Since they integrate so seamlessly with EC2 instances, we don't have to worry about telling the AWS Load Balancers about new instances or ones that we remove. It'll keep track of that for us. It'll also keep track of session data, perform health checks, and return metrics. All sorts of things.
"But how do I set up and send traffic to the Load Balancer?"
With a load balancer set up, instead of pointing traffic to any individual server, you'd now point it to the load balancer itself. Again, it's just another server, so if its IP address was something like 13.14.15.16, and your load balancing software was listening on port 3000, that's where you'd direct things. Obviously you'd want to leverage DNS and give it a friendly URL, but after that it would work to balance traffic between the servers behind it.
"But wait, how does it know about what servers to send it to?"
You tell it about them. Again, in the case of load balancers that you can use on AWS, a lot of that is taken care of for you.
Conclusion
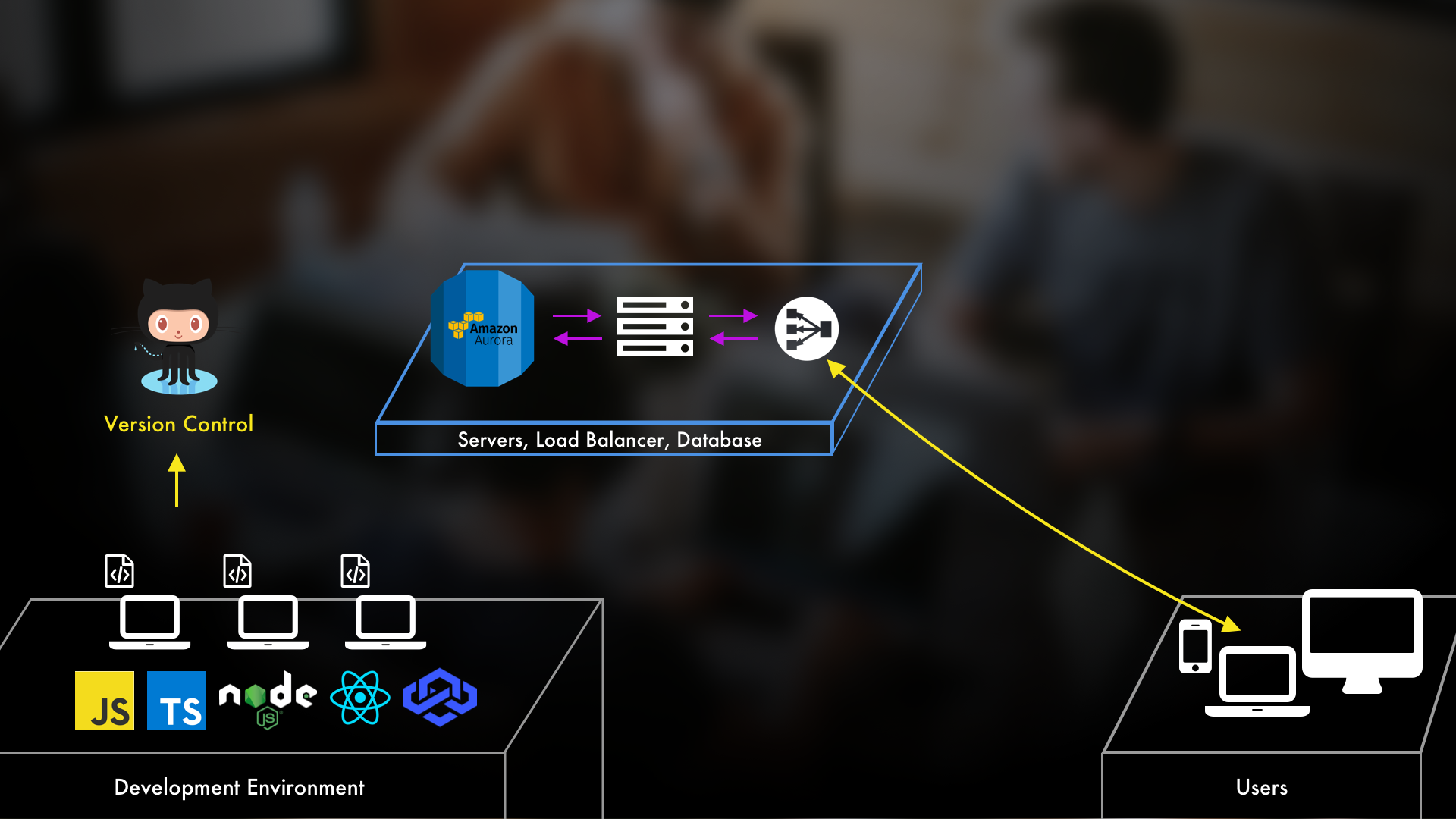
With that done, we've really set ourselves up for success. Quite frankly, between an Auto Scaling Group, RDS Aurora Database, and a Load Balancer, you could take this application very, very far. I'd say a lot of the more basic applications could even stop right here if they wanted to.
But we're going to keep going further. When it comes to updating and patching these machines, deploying new versions of our applications, or deploying new services and apps...we can do better. And, we can do so pretty painlessly using Docker and Containers which is coming up in the next series post.
Watch Instead of Read on Youtube
If you'd like to watch instead of read, the Understanding Modern Cloud Architecture series is also on YouTube! Check out the links below for the sections covered in this blog post.
Video 1 - Servers on EC2 and Databases (for sections 1-3)
Video 2 - Server Fleets, Auto Scaling Groups, and Load Balancers (for sections 4-6)
Other Posts in This Series
If you're enjoying this series and finding it useful, be sure to check out the rest of the blog posts in it! The links below will take you to the other posts in the Understanding Modern Cloud Architecture series here on Tech Guides and Thoughts so you can continue building your infrastructure along with me.
- Understanding Modern Cloud Architecture on AWS: A Concepts Series
- Understanding Modern Cloud Architecture on AWS: Server Fleets and Databases
- Understanding Modern Cloud Architecture on AWS: Docker and Containers
- Interlude - From Plain Machines to Container Orchestration: A Complete Explanation
- Understanding Modern Cloud Architecture on AWS: Container Orchestration with ECS
- Understanding Modern Cloud Architecture on AWS: Storage and Content Delivery Networks
Enjoy Posts Like These? Sign up to my mailing list!

J Cole Morrison
http://start.jcolemorrison.comDeveloper Advocate @HashiCorp, DevOps Enthusiast, Startup Lover, Teaching at awsdevops.io